第14讲 | HTTP协议
前面讲述完 传输层,接下来开始讲 应用层 的协议。从哪里开始讲呢,就从咱们最常用的HTTP协议开始。
HTTP协议,几乎是每个人上网用的第一个协议,同时也是很容易被人忽略的协议。
既然说看新闻,咱们就先登录 http://www.163.com 。
http://www.163.com 是个URL,叫作 统一资源定位符。之所以叫统一,是因为它是有格式的。HTTP称为协议,www.163.com是一个域名,表示互联网上的一个位置。有的URL会有更详细的位置标识,例如 http://www.163.com/index.html 。正是因为这个东西是统一的,所以当你把这样一个字符串输入到浏览器的框里的时候,浏览器才知道如何进行统一处理。
HTTP请求的准备
浏览器会将www.163.com这个域名发送给DNS服务器,让它解析为IP地址。那接下来是发送HTTP请求吗?
不是的,HTTP是基于TCP协议的,当然是要先建立TCP连接了,怎么建立呢?还记得第11节讲过的三次握手吗?
目前使用的HTTP协议大部分都是1.1。在1.1的协议里面,默认是开启了Keep-Alive的,这样建立的TCP连接,就可以在多次请求中复用。
学习了TCP之后,你应该知道,TCP的三次握手和四次挥手,还是挺费劲的。如果好不容易建立了连接,然后就做了一点儿事情就结束了,有点儿浪费人力和物力。
HTTP请求的构建
建立了连接以后,浏览器就要发送HTTP的请求。
请求的格式就像这样。

HTTP的报文大概分为三大部分。第一部分是 请求行,第二部分是请求的 首部,第三部分才是请求的 正文实体。
第一部分:请求行
在请求行中,URL就是 http://www.163.com ,版本为HTTP 1.1。这里要说一下的,就是方法。方法有几种类型。
对于访问网页来讲,最常用的类型就是 GET。GET就是去服务器获取一些资源。对于访问网页来讲,要获取的资源往往是一个页面。其实也有很多其他的格式,比如说返回一个JSON字符串,到底要返回什么,是由服务器端的实现决定的。
例如,在云计算中,如果我们的服务器端要提供一个基于HTTP协议的API,获取所有云主机的列表,这就会使用GET方法得到,返回的可能是一个JSON字符串。字符串里面是一个列表,列表里面是一项的云主机的信息。
另外一种类型叫做 POST。它需要主动告诉服务端一些信息,而非获取。要告诉服务端什么呢?一般会放在正文里面。正文可以有各种各样的格式。常见的格式也是JSON。
例如,我们下一节要讲的支付场景,客户端就需要把“我是谁?我要支付多少?我要买啥?”告诉服务器,这就需要通过POST方法。
再如,在云计算里,如果我们的服务器端,要提供一个基于HTTP协议的创建云主机的API,也会用到POST方法。这个时候往往需要将“我要创建多大的云主机?多少CPU多少内存?多大硬盘?”这些信息放在JSON字符串里面,通过POST的方法告诉服务器端。
还有一种类型叫 PUT,就是向指定资源位置上传最新内容。但是,HTTP的服务器往往是不允许上传文件的,所以PUT和POST就都变成了要传给服务器东西的方法。
在实际使用过程中,这两者还会有稍许的区别。POST往往是用来创建一个资源的,而PUT往往是用来修改一个资源的。
例如,云主机已经创建好了,我想对这个云主机打一个标签,说明这个云主机是生产环境的,另外一个云主机是测试环境的。那怎么修改这个标签呢?往往就是用PUT方法。
再有一种常见的就是 DELETE。就是用来删除资源的。例如,我们要删除一个云主机,就会调用DELETE方法。
第二部分:首部字段
请求行下面就是我们的首部字段。首部是key value,通过冒号分隔。这里面,往往保存了一些非常重要的字段。
例如, Accept-Charset,表示 客户端可以接受的字符集。防止传过来的是另外的字符集,从而导致出现乱码。
再如, Content-Type 是指 正文的格式。例如,我们进行POST的请求,如果正文是JSON,那么我们就应该将这个值设置为JSON。
这里需要重点说一下的就是 缓存。为啥要使用缓存呢?那是因为一个非常大的页面有很多东西。
例如,我浏览一个商品的详情,里面有这个商品的价格、库存、展示图片、使用手册等等。商品的展示图片会保持较长时间不变,而库存会根据用户购买的情况经常改变。如果图片非常大,而库存数非常小,如果我们每次要更新数据的时候都要刷新整个页面,对于服务器的压力就会很大。
对于这种高并发场景下的系统,在真正的业务逻辑之前,都需要有个接入层,将这些静态资源的请求拦在最外面。
这个架构的图就像这样。
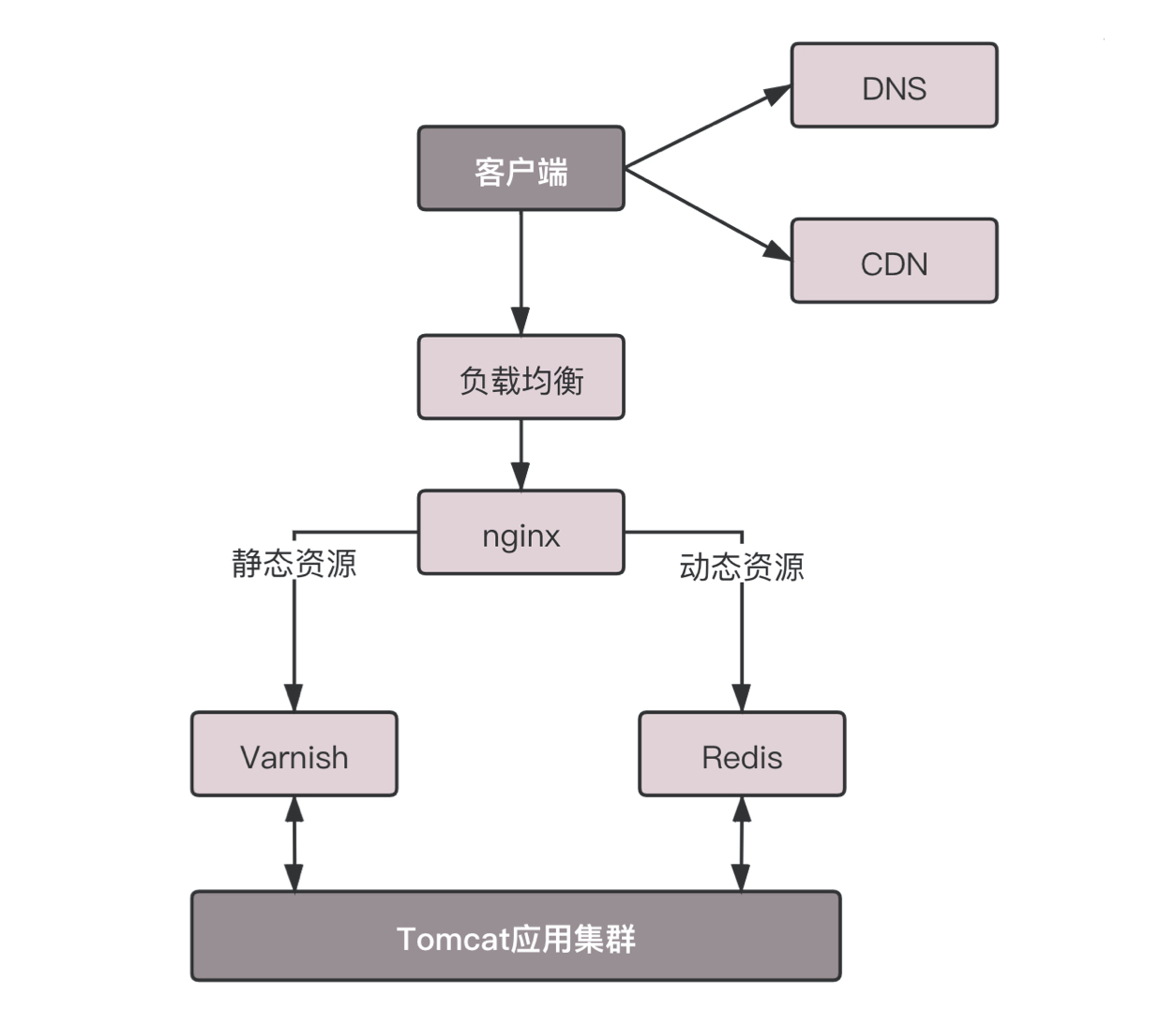
其中DNS、CDN我在后面的章节会讲。和这一节关系比较大的就是Nginx这一层,它如何处理HTTP协议呢?对于静态资源,有Vanish缓存层。当缓存过期的时候,才会访问真正的Tomcat应用集群。
在HTTP头里面, Cache-control 是用来 控制缓存 的。当客户端发送的请求中包含max-age指令时,如果判定缓存层中,资源的缓存时间数值比指定时间的数值小,那么客户端可以接受缓存的资源;当指定max-age值为0,那么缓存层通常需要将请求转发给应用集群。
具体来说:
- 当客户端发送带有
Cache-Control: max-age=<seconds>的请求时,它实际上是告诉缓存(可能是本地浏览器缓存或者是中间代理缓存),只有那些在指定秒数内被缓存的响应才是有效的,即资源的最后缓存时间距离当前时间不超过<seconds>秒。
例如,假设客户端发送这样的请求头:
Http
Cache-Control: max-age=3600
这意味着客户端仅接受在过去1小时(3600秒)内缓存的资源。如果缓存中有匹配的资源且其缓存时间未超过1小时,那么缓存可以直接返回这个资源给客户端,无需再次向服务器请求。
- 当
max-age设置为0时,这实际上是一个特殊的指令,意味着客户端要求获取最新的资源副本,不接受任何缓存的内容。缓存应当忽略其内部存储的任何对应资源,转而直接向原始服务器发出请求以获取最新版本。
例如:
Http
Cache-Control: max-age=0
在此情况下,即使缓存中存在该资源,由于max-age为0,缓存系统应当认为所有现有缓存的该资源都已过期,因此会将请求转发至应用服务器集群以获取最新版本的资源。这样做的目的是确保客户端能够获得服务器上的实时数据,而不是依赖可能已经过时的缓存版本。
另外, If-Modified-Since 也是一个关于缓存的。也就是说,如果服务器的资源在某个时间之后更新了,那么客户端就应该下载最新的资源;如果没有更新,服务端会返回“304 Not Modified”的响应,那客户端就不用下载了,也会节省带宽。
到此为止,我们仅仅是拼凑起了HTTP请求的报文格式,接下来,浏览器会把它交给下一层传输层。怎么交给传输层呢?其实也无非是用Socket这些东西,只不过用的浏览器里,这些程序不需要你自己写,有人已经帮你写好了。
HTTP请求的发送
HTTP协议是基于TCP协议的,所以它使用面向连接的方式发送请求,通过stream二进制流的方式传给对方。当然,到了TCP层,它会把二进制流变成一个个报文段发送给服务器。
在发送给每个报文段的时候,都需要对方有一个回应ACK,来保证报文可靠地到达了对方。如果没有回应,那么TCP这一层会进行重新传输,直到可以到达。同一个包有可能被传了好多次,但是HTTP这一层不需要知道这一点,因为是TCP这一层在埋头苦干。
TCP层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址),将这两个信息放到IP头里面,交给IP层进行传输。
IP层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送ARP协议来请求这个目标地址对应的MAC地址,然后将源MAC和目标MAC放入MAC头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送ARP协议,来获取网关的MAC地址,然后将源MAC和网关MAC放入MAC头,发送出去。
网关收到包发现MAC符合,取出目标IP地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的MAC地址,将包发给下一跳路由器。
这样路由器一跳一跳终于到达目标的局域网。这个时候,最后一跳的路由器能够发现,目标地址就在自己的某一个出口的局域网上。于是,在这个局域网上发送ARP,获得这个目标地址的MAC地址,将包发出去。
目标的机器发现MAC地址符合,就将包收起来;发现IP地址符合,根据IP头中协议项,知道自己上一层是TCP协议,于是解析TCP的头,里面有序列号,需要看一看这个序列包是不是我要的,如果是就放入缓存中然后返回一个ACK,如果不是就丢弃。
TCP头里面还有端口号,HTTP的服务器正在监听这个端口号。于是,目标机器自然知道是HTTP服务器这个进程想要这个包,于是将包发给HTTP服务器。HTTP服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
HTTP返回的构建
HTTP的返回报文也是有一定格式的。这也是基于HTTP 1.1的。
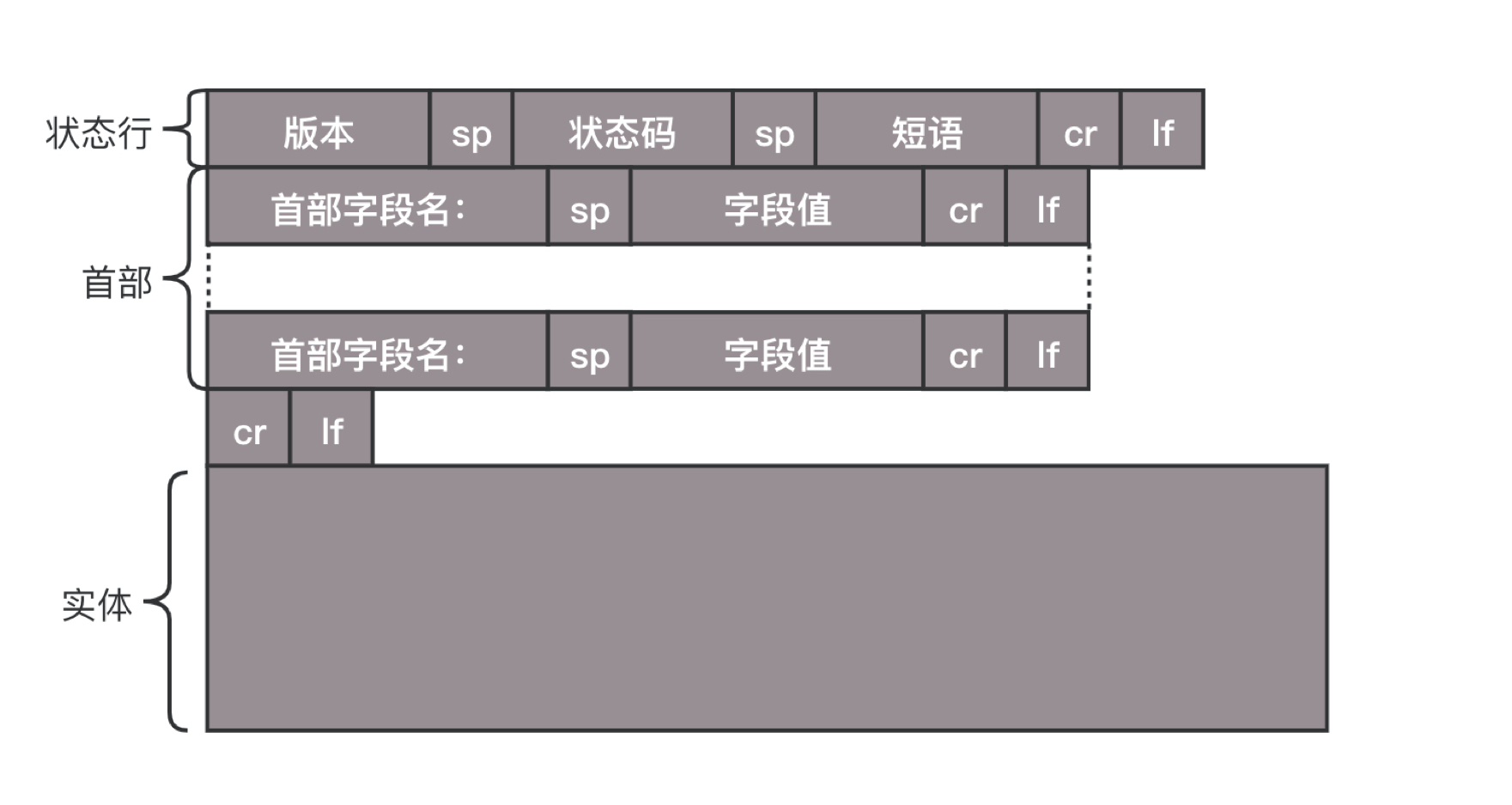
状态码会反映HTTP请求的结果。“200”意味着大吉大利;而我们最不想见的,就是“404”,也就是“服务端无法响应这个请求”。然后,短语会大概说一下原因。
接下来是返回首部的 key value。
这里面, Retry-After 表示,告诉客户端应该在多长时间以后再次尝试一下。“503错误”是说“服务暂时不再和这个值配合使用”。
在返回的头部里面也会有 Content-Type,表示返回的是HTML,还是JSON。
构造好了返回的HTTP报文,接下来就是把这个报文发送出去。还是交给Socket去发送,还是交给TCP层,让TCP层将返回的HTML,也分成一个个小的段,并且保证每个段都可靠到达。
这些段加上TCP头后会交给IP层,然后把刚才的发送过程反向走一遍。虽然两次不一定走相同的路径,但是逻辑过程是一样的,一直到达客户端。
客户端发现MAC地址符合、IP地址符合,于是就会交给TCP层。根据序列号看是不是自己要的报文段,如果是,则会根据TCP头中的端口号,发给相应的进程。这个进程就是浏览器,浏览器作为客户端也在监听某个端口。
当浏览器拿到了HTTP的报文。发现返回“200”,一切正常,于是就从正文中将HTML拿出来。HTML是一个标准的网页格式。浏览器只要根据这个格式,展示出一个绚丽多彩的网页。
这就是一个正常的HTTP请求和返回的完整过程。
HTTP 2.0
当然HTTP协议也在不断的进化过程中,在HTTP1.1基础上便有了HTTP 2.0。
HTTP 1.1在应用层以纯文本的形式进行通信。每次通信都要带完整的HTTP的头,而且不考虑pipeline模式的话,每次的过程总是像上面描述的那样一去一回。这样在实时性、并发性上都存在问题。
为了解决这些问题,HTTP 2.0会对HTTP的头进行一定的压缩,将原来每次都要携带的大量key value在两端建立一个索引表,对相同的头只发送索引表中的索引。
另外,HTTP 2.0协议将一个TCP的连接中,切分成多个流,每个流都有自己的ID,而且流可以是客户端发往服务端,也可以是服务端发往客户端。它其实只是一个虚拟的通道。流是有优先级的。
HTTP 2.0还将所有的传输信息分割为更小的消息和帧,并对它们采用二进制格式编码。常见的帧有 Header帧,用于传输Header内容,并且会开启一个新的流。再就是 Data帧,用来传输正文实体。多个Data帧属于同一个流。
通过这两种机制,HTTP 2.0的客户端可以将多个请求分到不同的流中,然后将请求内容拆成帧,进行二进制传输。这些帧可以打散乱序发送, 然后根据每个帧首部的流标识符重新组装,并且可以根据优先级,决定优先处理哪个流的数据。
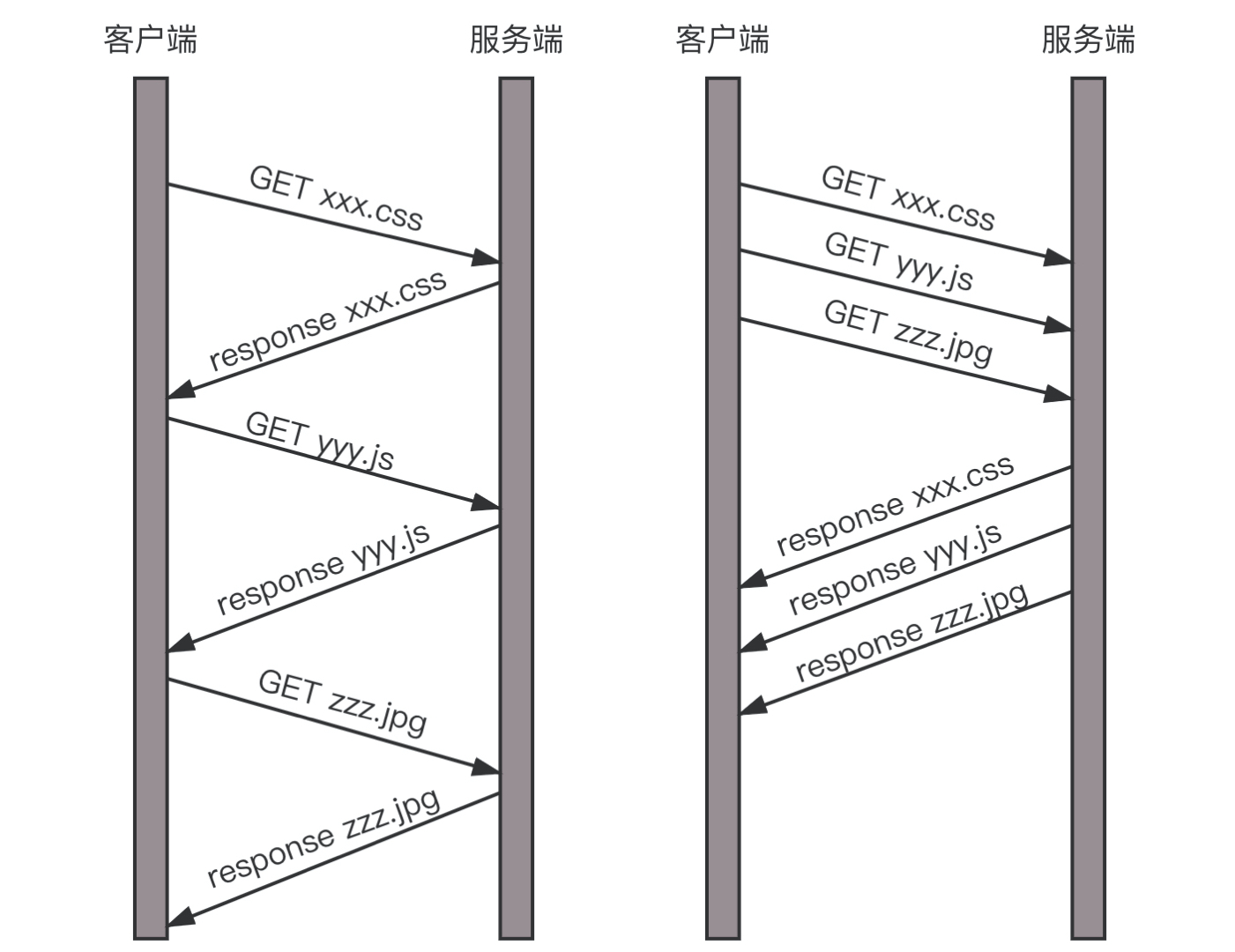
我们来举一个例子。
假设我们的一个页面要发送三个独立的请求,一个获取css,一个获取js,一个获取图片jpg。如果使用HTTP 1.1就是串行的,但是如果使用HTTP 2.0,就可以在一个连接里,客户端和服务端都可以同时发送多个请求或回应,而且不用按照顺序一对一对应。
HTTP 2.0其实是将三个请求变成三个流,将数据分成帧,乱序发送到一个TCP连接中。
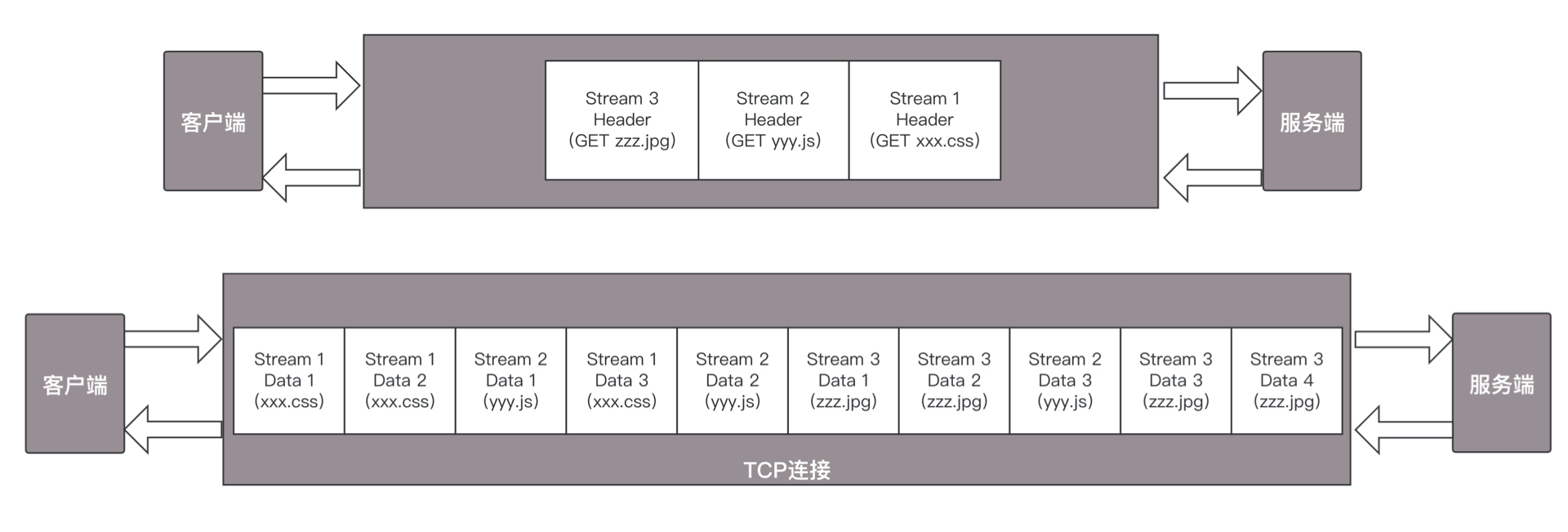
HTTP 2.0成功解决了HTTP 1.1的队首阻塞问题,同时,也不需要通过HTTP 1.x的pipeline机制用多条TCP连接来实现并行请求与响应;减少了TCP连接数对服务器性能的影响,同时将页面的多个数据css、js、 jpg等通过一个数据链接进行传输,能够加快页面组件的传输速度。
HTTP/1.1 与 HTTP/2 的主要区别在于其底层传输机制和性能优化手段的不同。HTTP/1.1 使用文本格式传输,每个TCP连接在同一时间只能处理一个请求,尽管支持Keep-Alive以复用连接,但仍存在队头阻塞问题,不支持请求的真正并行处理,且头部信息未被压缩。相比之下,HTTP/2 采用了二进制分帧传输机制,通过多路复用技术在一个TCP连接上并发处理多个请求和响应,消除了队头阻塞现象,大大提高了数据传输效率。此外,HTTP/2 引入了头部压缩、服务器推送功能,并允许为每个流设置优先级,这些改进进一步优化了网络性能和用户体验。
HTTP2带来的好处包括:
更高的性能:多路复用显著提升了页面加载速度,尤其对于包含大量资源的现代网站而言,减少了延迟和整体加载时间。
头部压缩:减少了网络传输的数据量,降低了带宽消耗。
优先级与依赖性管理:允许浏览器确定哪些资源更重要,优先下载关键资源,有助于提升页面渲染速度。
服务器推送:服务器能够预测客户端所需资源,并预先将其推送给客户端,减少往返时间和网络延迟。
更好的连接利用率:通过在一个TCP连接上传输多个请求和响应,提高了网络连接的利用效率,同时也减少了建立和管理多个连接的开销。
HTTP/1.1 和 HTTP/2 是两种不同的超文本传输协议版本,它们在设计和性能优化方面存在显著区别:
HTTP/1.1(1999年发布)
连接管理:
- 默认保持连接(Persistent Connections / Keep-Alive),但每个TCP连接一次只能处理一个请求-响应事务,导致串行化问题,尤其是在网页包含大量资源时造成“队头阻塞”。
头部压缩:
- HTTP/1.1 不内置头部压缩机制,重复的头部信息会导致额外的网络流量。
管道化(Pipelining):
- 尽管HTTP/1.1支持管道化以改善请求顺序问题,但在实践中很少使用,因为它无法解决乱序响应的问题,而且在错误处理和优先级管理上存在问题。
缓存控制:
- 提供了丰富的缓存机制,如
Cache-Control、ETag和Last-Modified等头字段。
- 提供了丰富的缓存机制,如
分块传输编码:
- 支持分块传输编码以适应未知大小的响应内容传输,但不适用于静态资源的小块并行传输。
HTTP/2(2015年发布)
二进制分帧传输:
- HTTP/2 引入了一种新的二进制分帧层,所有HTTP消息都被分解成一个个帧,极大地提高了协议解析效率。
多路复用(Multiplexing):
- 同一个TCP连接上可以同时处理多个请求和响应,解决了队头阻塞问题,使得请求能够并行传输,提高了资源加载速度。
头部压缩:
- 使用HPACK压缩算法专门压缩HTTP头部,有效减少了网络传输量。
服务器推送:
- 服务器能预测客户端可能需要的资源,并提前推送这些资源到客户端,减少延迟。
流优先级:
- 允许为每个流分配优先级,使得重要资源能够更快地到达客户端。
保留HTTP/1.1语义:
- 虽然底层传输方式改变,但HTTP/2仍与HTTP/1.1语义兼容,支持相同的HTTP方法、状态码、URI和头字段等。
综上所述,HTTP/2在很大程度上改进了HTTP/1.1的性能瓶颈,提升了Web应用的整体性能体验。
QUIC协议的“城会玩”
HTTP 2.0虽然大大增加了并发性,但还是有问题的。因为HTTP 2.0也是基于TCP协议的,TCP协议在处理包时是有严格顺序的。
当其中一个数据包遇到问题,TCP连接需要等待这个包完成重传之后才能继续进行。虽然HTTP 2.0通过多个stream,使得逻辑上一个TCP连接上的并行内容,进行多路数据的传输,然而这中间并没有关联的数据。一前一后,前面stream 2的帧没有收到,后面stream 1的帧也会因此阻塞。
于是,就又到了从TCP切换到UDP,进行“城会玩”的时候了。这就是Google的QUIC协议,接下来我们来看它是如何“城会玩”的。
机制一:自定义连接机制
我们都知道,一条TCP连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口。一旦一个元素发生变化时,就需要断开重连,重新连接。在移动互联情况下,当手机信号不稳定或者在WIFI和 移动网络切换时,都会导致重连,从而进行再次的三次握手,导致一定的时延。
这在TCP是没有办法的,但是基于UDP,就可以在QUIC自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个64位的随机数作为ID来标识,而且UDP是无连接的,所以当IP或者端口变化的时候,只要ID不变,就不需要重新建立连接。
机制二:自定义重传机制
前面我们讲过,TCP为了保证可靠性,通过使用 序号 和 应答 机制,来解决顺序问题和丢包问题。
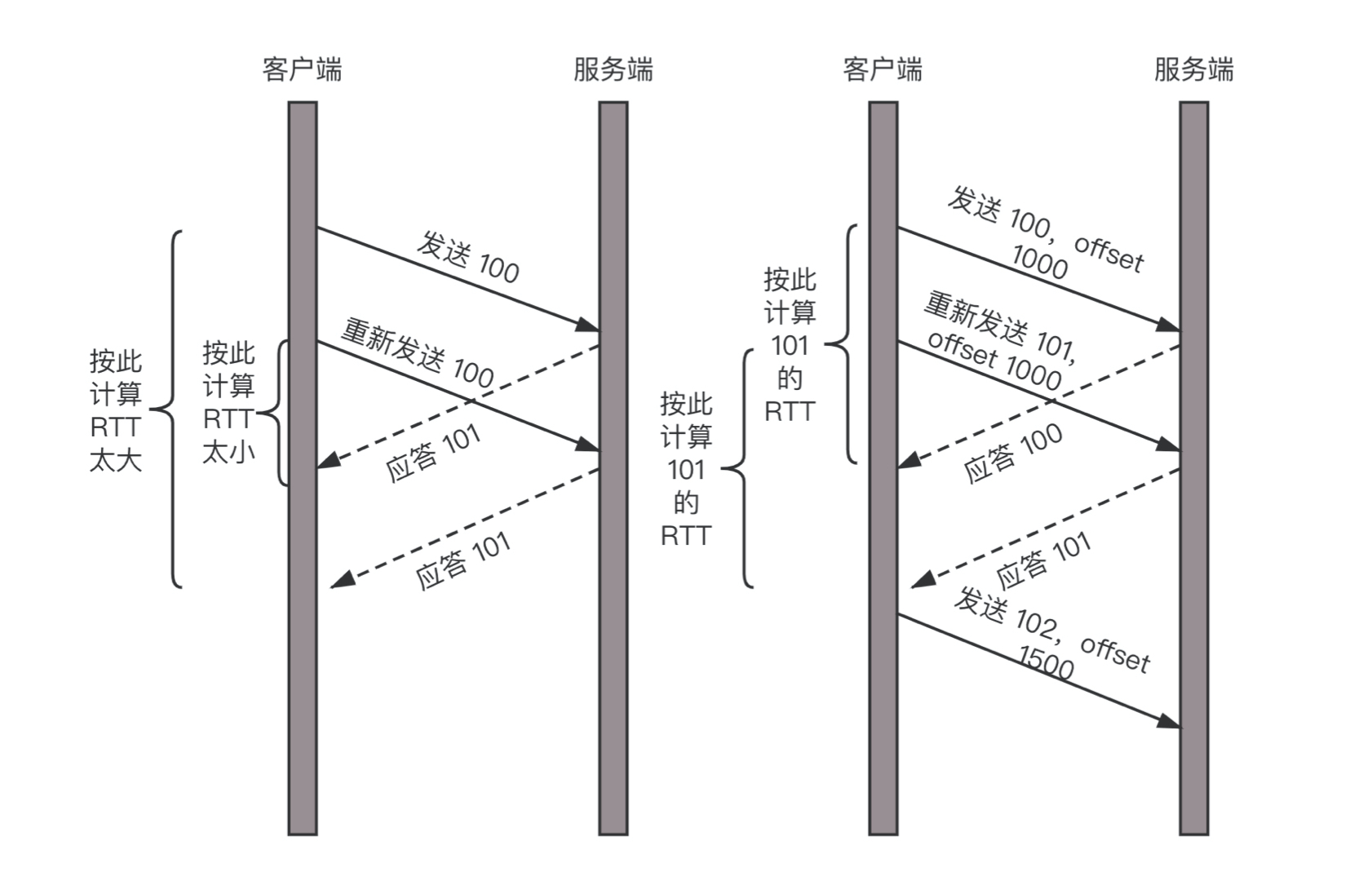
任何一个序号的包发过去,都要在一定的时间内得到应答,否则一旦超时,就会重发这个序号的包。那怎么样才算超时呢?还记得我们提过的 自适应重传算法 吗?这个超时是通过 采样往返时间RTT 不断调整的。
其实,在TCP里面超时的采样存在不准确的问题。例如,发送一个包,序号为100,发现没有返回,于是再发送一个100,过一阵返回一个ACK101。这个时候客户端知道这个包肯定收到了,但是往返时间是多少呢?是ACK到达的时间减去后一个100发送的时间,还是减去前一个100发送的时间呢?事实是,第一种算法把时间算短了,第二种算法把时间算长了。
QUIC也有个序列号,是递增的。任何一个序列号的包只发送一次,下次就要加一了。例如,发送一个包,序号是100,发现没有返回;再次发送的时候,序号就是101了;如果返回的ACK 100,就是对第一个包的响应。如果返回ACK 101就是对第二个包的响应,RTT计算相对准确。
但是这里有一个问题,就是怎么知道包100和包101发送的是同样的内容呢?QUIC定义了一个offset概念。QUIC既然是面向连接的,也就像TCP一样,是一个数据流,发送的数据在这个数据流里面有个偏移量offset,可以通过offset查看数据发送到了哪里,这样只要这个offset的包没有来,就要重发;如果来了,按照offset拼接,还是能够拼成一个流。
机制三:无阻塞的多路复用
有了自定义的连接和重传机制,我们就可以解决上面HTTP 2.0的多路复用问题。
同HTTP 2.0一样,同一条QUIC连接上可以创建多个stream,来发送多个 HTTP 请求。但是,QUIC是基于UDP的,一个连接上的多个stream之间没有依赖。这样,假如stream2丢了一个UDP包,后面跟着stream3的一个UDP包,虽然stream2的那个包需要重传,但是stream3的包无需等待,就可以发给用户。
机制四:自定义流量控制
TCP的流量控制是通过 滑动窗口协议。QUIC的流量控制也是通过window_update,来告诉对端它可以接受的字节数。但是QUIC的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个stream控制窗口。
还记得吗?在TCP协议中,接收端的窗口的起始点是下一个要接收并且ACK的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为TCP的ACK机制是基于序列号的累计应答,一旦ACK了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
QUIC的ACK是基于offset的,每个offset的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空档会等待到来或者重发即可,而窗口的起始位置为当前收到的最大offset,从这个offset到当前的stream所能容纳的最大缓存,是真正的窗口大小。显然,这样更加准确。
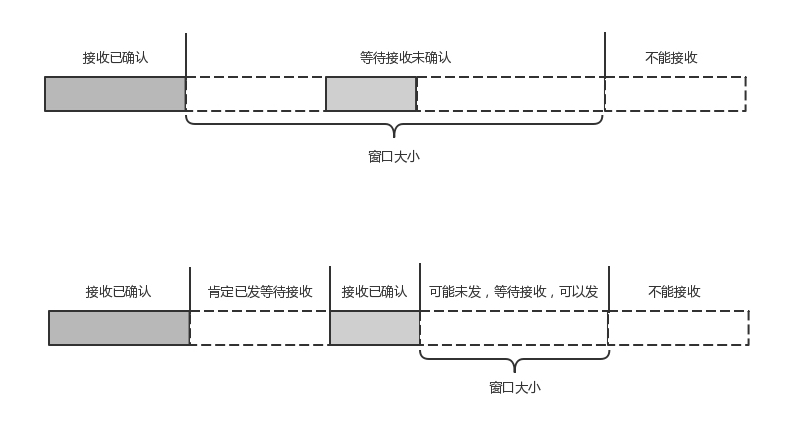
另外,还有整个连接的窗口,需要对于所有的stream的窗口做一个统计。
小结
HTTP协议虽然很常用,也很复杂,重点记住GET、POST、 PUT、DELETE这几个方法,以及重要的首部字段;
HTTP 2.0通过头压缩、分帧、二进制编码、多路复用等技术提升性能;
QUIC协议通过基于UDP自定义的类似TCP的连接、重试、多路复用、流量控制技术,进一步提升性能。
QUIC是一个精巧的协议,所以它肯定不止今天我提到的四种机制,你知道它还有哪些吗?
多路复用与流控:
- QUIC在单个UDP连接上实现了多路复用,每个数据流都有自己的独立序列号和流控,可以独立地进行数据传输和确认,从而避免了HTTP/2中HEADERS帧的队头阻塞问题。
0-RTT启动:
- QUIC允许在某些情况下在重新连接时实现0-RTT(零往返时间)数据传输,即在建立安全连接的同时发送应用数据,显著降低首次或重连后的延迟。
前向纠错(FEC):
- QUIC支持可选的前向纠错,允许恢复部分丢失的数据包而无需等待重传,特别适用于高丢包率的网络环境。
连接迁移:
- QUIC允许连接在IP地址发生变化时(例如Wi-Fi和蜂窝网络切换)保持活跃,提供了更好的移动设备支持。
安全性增强:
- QUIC集成了TLS加密机制,并进行了改进,例如QUIC TLS握手更快,且每个新的加密密钥材料仅应用于未来的数据,增强了安全性。
更灵活的拥塞控制:
- QUIC自带拥塞控制算法,相比于TCP的单一全局拥塞窗口,QUIC的每个数据流有自己的独立拥塞控制器,可以更细粒度地调整和优化传输速率。
轻量级重传机制:
- QUIC使用基于Packet Number(PN)的序列号,通过ACK帧快速反馈丢失的数据包,并支持快速重传和早退机制。
基于时间的丢包检测:
- QUIC引入了一个时间戳机制,可以更准确地检测和处理丢包,尤其是对网络抖动具有更强的适应能力。
更快速的握手:
- QUIC握手过程被设计得更加简洁,减少了建立连接所需的时间,特别是在多次请求时,可以复用先前的连接信息。
以上列举了QUIC协议相较于传统TCP/IP协议栈的一些重要改进和新增功能,使其在网络传输效率、连接迁移、安全性以及降低延迟等方面表现优秀。随着协议的不断发展和完善,QUIC还可能包含更多高级特性来适应不断变化的网络环境需求。
这一节主要讲了如何基于HTTP浏览网页,如果要传输比较敏感的银行卡信息,该怎么办呢?

